
Computer & Vision Research Center
Established in 1980, the Computer and Vision Research Center (CVRC) is devoted to the analysis and understanding of images, signals, and data, and to the development of the computer resources required to accomplish these tasks. Research objectives include the development of computational models, algorithms, and architectures for computer vision. Current Center activities include projects in automatic target recognition and automatic recognition of human motion and interactions.
Results of the Center's research are presented at national and international conferences and published in technical reports, scientific journals, and books. Reprints of recent reports and journal publications are available upon request.
The goal of this project is to construct a general methodology that is applicable for the recognition of human activities. We especially focus on the semantic-level analysis, toward recognition of high-level activities with complex temporal, spatial, and logical structure.

Of increasing interest to the computer vision community is to recognize egocentric actions. Conceptually, an egocentric action is largely identifiable by the states of hands and objects. For example, “drinking soda” is essentially composed of two sequential states where one first "takes up the soda can", then "drinks from the soda can". While existing algorithms commonly use manually defined states to train action classifiers, we present a novel model that automatically mines discriminative states for recognizing egocentric actions. To mine discriminative states, we propose a novel kernel function and formulate a Multiple Kernel Learning based framework to learn adaptive weights for different states. Experiments on three benchmark datasets, i.e., RGBD-Ego, ADL, and GTEA, clearly show that our recognition algorithm outperforms state-of-the-art algorithms.
Shaohua Wan, and J.K. Aggarwal, "Mining Discriminative States of Hands and Objects to Recognize Egocentric Actions with a Wearable RGBD Camera.", 26th IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops 2015), Boston, US, June 2015

Recognition of human actions from a distant view is a challenging problem in computer vision. The available visual cues are particularly sparse and vague under this scenario. We proposed an action descriptor, which is composed of time series of subspace projected histogram-based features. Our descriptor combines both human poses and motion information and performs feature selection in a supervised fashion. Our method has been tested on several public datasets and achieves very promising accuracy.
C.-C. Chen and J. K. Aggarwal, "Recognizing Human Action from a Far Field of View", IEEE Workshop on Motion and Video Computing (WMVC), Utah, USA, December 2009.
M. M. S. Ryoo, C.-C. Chen, J. K. Aggarwal, and A. Roy-Chowdhury, "An Overview of Contest on Semantic Description of Human Activities (SDHA) 2010", International Conference on Pattern Recognition (ICPR) Contests, August 2010.

The success in human shadow removal leads to the accurate recognition of activities and the robust tracking of people. We present a shadow removal technique which effectively eliminates human shadow cast from an unknown direction of light source. A multi-cue shadow descriptor is proposed to characterize the distinctive properties of shadow. We employ a 3-stage process to detect then remove shadow. Our algorithm further improves the shadow detection accuracy by imposing the spatial constraint between the foreground subregions of human and shadow.
C.-C. Chen and J. K. Aggarwal, "Human Shadow Removal with Unknown Light Source",International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, August 2010.

In this work, we propose a template-based algorithm for recognizing box-like objects. Our technique is invariant to scale, rotation and translation as well as robust to patterned surfaces and moderate occlusions. We reassemble box-like segments from an over-segmented image. The shapes and inner edges of the merged box-like segments are verified seprartly with the orresponding templates. We formulate the process of template matching into an optimization problem, and propose a combined metric to evaluate the similarity.
C.-C. Chen and J. K. Aggarwal, "Recognition of Box-like Objects by Fusing Cues of Shape and Edges", International Conference on Pattern Recognition (ICPR), Tampa, FL, December 2008.

Background subtraction is an essential element in most object tracking and video surveillance systems. The success of this low-level processing step is highly dependent on the quality of the background model maintained. We present a background initialization algorithm which identifies stable intervals of intensity values at each pixel, and determines which interval is most likely to display background. Our method is adaptive to the scale of foregound motion and is able to equalize the uneven effect caused by different object depths. Our method achieves promising results even with complex foreground contents.
C.-C. Chen and J. K. Aggarwal, "An Adaptive Background Model Initialization Algorithm with Objects Moving at Different Depths", IEEE International Conference on Image Processing (ICIP), San Diego, CA, October 2008.
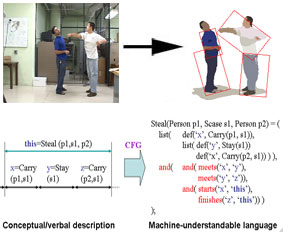
We have developed a new language-based approach for the recognition of high-level interactions between two persons. A human activity is represented by decomposing it into multiple sub-events and by specifying their necessary relationships(temporal, spatial, and logical ), and is recognized by matching the representation with input videos. Sub-events of one activity may be composed of multiple sub-events of itself, capturing the hierarchical structure of human activities. As a result, continued and recursive activities such as 'fighting', 'greeting', 'assault', and 'pursuit' of two persons are recognized.
M. S. Ryoo and J. K. Aggarwal, "Recognition of Composite Human Activities through Context-Free Grammar based Representation", Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Vol. 2, pp. 1709-1719, New York, NY, 2006.
M. S. Ryoo and J. K. Aggarwal, "Semantic Understanding of Continued and Recursive Human Activities", Proceedings of 18th International Conference on Pattern Recognition (ICPR), Vol. 1, pp. 379~382, Hong Kong, 2006
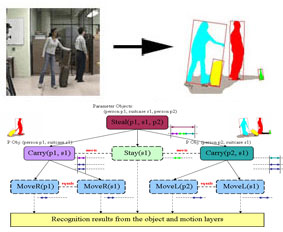
The framework is extended for the recognition of interactions between humans and multiple objects. Human activities involving objects, such as "a person stealing another's suitcase", are recognized by considering objects and their motion. Ability to probabilistically compensate for the failure of its components (object recognition for example) is given to the system for more reliable recognition.
M. S. Ryoo and J. K. Aggarwal, "Hierarchical Recognition of Human Activities Interacting with Objects", Proceedings of 2nd International Workshop on Semantic Learning Applications in Multimedia (SLAM), in conjunction with CVPR, Minneapolis, MN, June 2007.
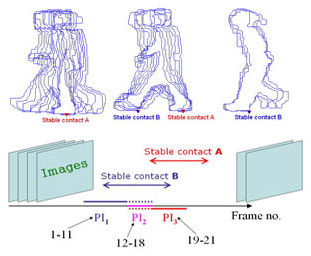
We propose a concept of stable contact for human motion analysis. Simply speaking, we find extreme points from a human contour first. Those extreme points that don't move (with a maximum position deviation w) for a long enough period (with a minimum duration threshold t) are detected as stable contacts. We use such a concept to characterize walking, running, climbing (fence, rock) etc. The rational behind is simple. A walking is a sequence where the number of stable contacts alternates between 1 and 2, in running it is usually 0 and 1, while in climbing it has some chances to be 3 or more.
Elden Yu, J. K. Aggarwal: Detection of Fence Climbing from Monocular Video. ICPR (1) 2006: 375-378
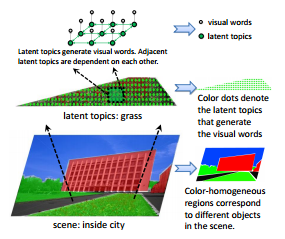
In this project, the latent topic model is used to cluster visual words under different semantically meaningful "topics" in an unsupervised manner. The histogram of latent topics is then used as input to train/test scene classifiers. Such an approach is demonstrated to give superior accuracy than a number of traditional scene recognition methods, including the basic Bag-of-Words (BoW) model.
Shaohua Wan and J.K. Aggarwal, "Scene Recognition by Jointly Modeling Latent Topics.", IEEE Winter Conference on Applications of Computer Vision (WACV2014), Steamboat Springs, CO, US, March 2014

The objective of this paper is to present on patch-based face recognition from video.The proposed solution includes aligning face patches to a template face using Lucas- Kanade image alignment algorithm. Our method then tries to stitch the face patches together, by a refinement of the alignment algorithm.Currently we were able to successfully recognize a reconstructed face from patches in a video, and there is great scope for furture work including changes in pose, illumination, and expression.
Changbo Hu, Josh Harguess, and J.K. Aggarwal, "Patch-based Face Recognition from Video", IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, November 2009.

We constructed an intelligent environment which visually observes tasks of users to help the users complete their tasks. The system is designed to analyze the status of ongoing tasks and to generate appropriate feedback guiding the user.
M. S. Ryoo and J. K. Aggarwal, "Robust Human-Computer Interaction System Guiding a User by Providing Feedback", Proceedings of International Joint Conference on Artificial Intelligence (IJCAI), Hyderabad, India, 2007.
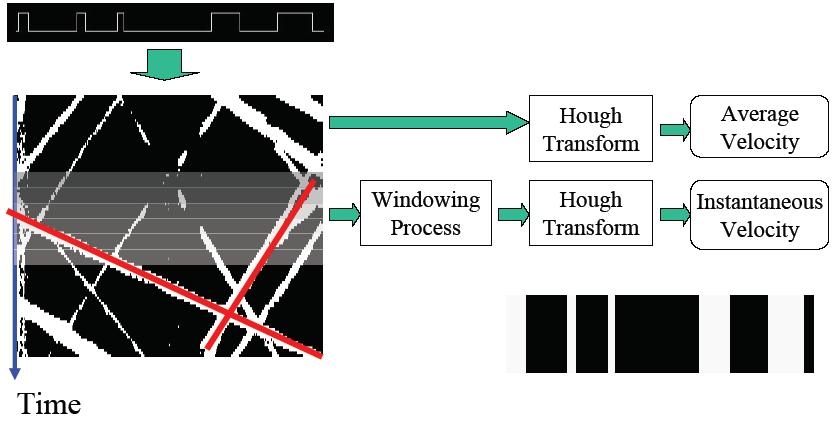
Temporal spatio-velocity (TSV) transform extracts pixel velocitities from images sequences, and groups pixels in similar velocities into a blob. As a result, blobs are segmented ven in severe occlusion based on their velocity information, and are tracked throughout the sequence. TSV has been applied for the tracking pedestrian, cars, and soccer players.
Koichi Sato, J. K. Aggarwal: Temporal spatio-velocity transform and its application to tracking and interaction. Computer Vision and Image Understanding 96(2): 100-128 (2004)